Example of an End-to-end Data Pipeline
We want to create ad appligation for analysis for a restaurant. Each day we receive a csv file containing this information

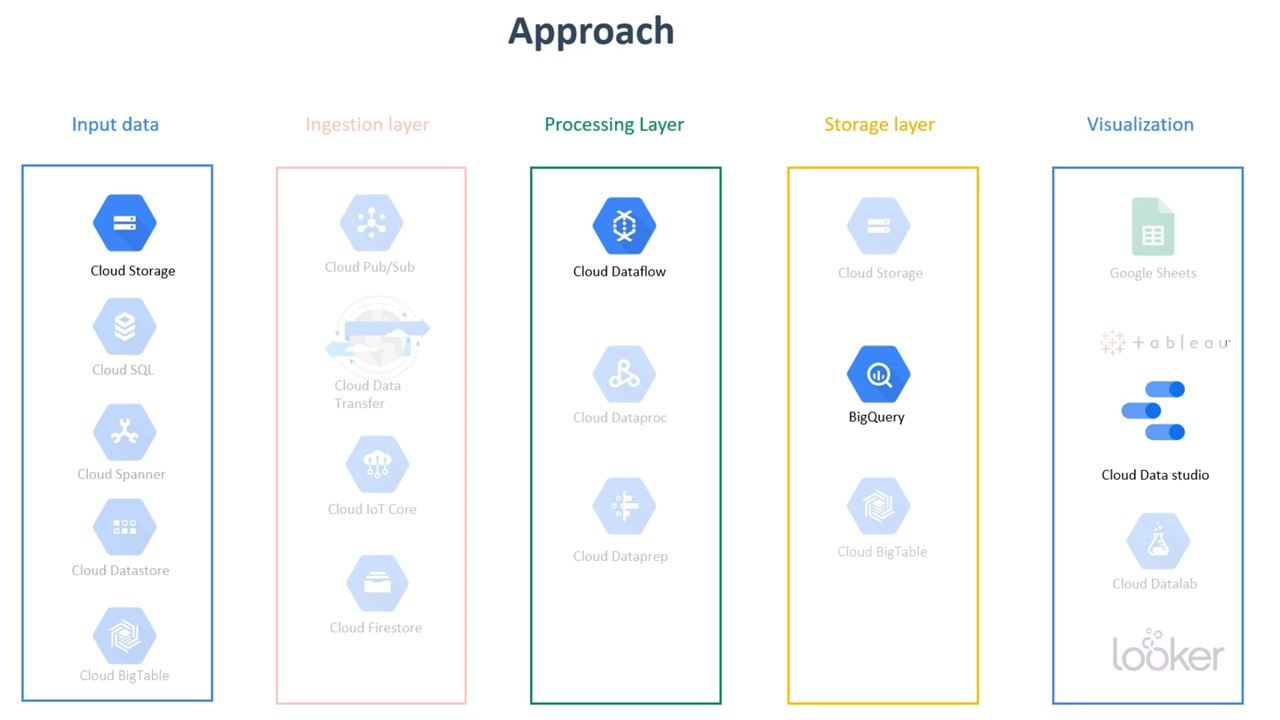
Our approach
Using Apache Beam
Apache Beam is an open source, unified model for defining both batch- and streaming-data parallel-processing pipelines. The Apache Beam programming model simplifies the mechanics of large-scale data processing
pip install apache-beam[gcp]
Code
Setup
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions, StandardOptions
import argparse
from google.cloud import bigquery
parser = argparse.ArgumentParser()
parser.add_argument('--input',
dest='input',
required=True,
help='Input file to process.')
path_args, pipeline_args = parser.parse_known_args()
inputs_pattern = path_args.input
options = PipelineOptions(pipeline_args)
Creating functions for cleaning data
def remove_last_colon(row): # OXJY167254JK,11-09-2020,8:11:21,854A854,Chow M?ein:,65,Cash,Sadabahar,Delivered,5,Awesome experience
cols = row.split(',') # [(OXJY167254JK) (11-11-2020) (8:11:21) (854A854) (Chow M?ein:) (65) (Cash) ....]
item = str(cols[4]) # item = Chow M?ein:
if item.endswith(':'):
cols[4] = item[:-1] # cols[4] = Chow M?ein
return ','.join(cols) # OXJY167254JK,11-11-2020,8:11:21,854A854,Chow M?ein,65,Cash,Sadabahar,Delivered,5,Awesome experience
def remove_special_characters(row): # oxjy167254jk,11-11-2020,8:11:21,854a854,chow m?ein,65,cash,sadabahar,delivered,5,awesome experience
import re
cols = row.split(',') # [(oxjy167254jk) (11-11-2020) (8:11:21) (854a854) (chow m?ein) (65) (cash) ....]
ret = ''
for col in cols:
clean_col = re.sub(r'[?%&]','', col)
ret = ret + clean_col + ',' # oxjy167254jk,11-11-2020,8:11:21,854a854,chow mein:,65,cash,sadabahar,delivered,5,awesome experience,
ret = ret[:-1] # oxjy167254jk,11-11-2020,8:11:21,854A854,chow mein:,65,cash,sadabahar,delivered,5,awesome experience
return ret
def print_row(row):
print row
Creating collections
delivered_orders = (
cleaned_data
| 'delivered filter' >> beam.Filter(lambda row: row.split(',')[8].lower() == 'delivered')
)
other_orders = (
cleaned_data
| 'Undelivered Filter' >> beam.Filter(lambda row: row.split(',')[8].lower() != 'delivered')
)
(cleaned_data
| 'count total' >> beam.combiners.Count.Globally() # 920
| 'total map' >> beam.Map(lambda x: 'Total Count:' +str(x)) # Total Count: 920
| 'print total' >> beam.Map(print_row)
)
(delivered_orders
| 'count delivered' >> beam.combiners.Count.Globally()
| 'delivered map' >> beam.Map(lambda x: 'Delivered count:'+str(x))
| 'print delivered count' >> beam.Map(print_row)
)
(other_orders
| 'count others' >> beam.combiners.Count.Globally()
| 'other map' >> beam.Map(lambda x: 'Others count:'+str(x))
| 'print undelivered' >> beam.Map(print_row)
)
Creating dataset and adding a table
client = bigquery.Client()
dataset_id = "{}.dataset_food_orders".format(client.project)
try:
client.get_dataset(dataset_id)
except:
dataset = bigquery.Dataset(dataset_id) #
dataset.location = "US"
dataset.description = "dataset for food orders"
dataset_ref = client.create_dataset(dataset, timeout=30) # Make an API request.
def to_json(csv_str):
fields = csv_str.split(',')
json_str = {"customer_id":fields[0],
"date": fields[1],
"timestamp": fields[2],
"order_id": fields[3],
"items": fields[4],
"amount": fields[5],
"mode": fields[6],
"restaurant": fields[7],
"status": fields[8],
"ratings": fields[9],
"feedback": fields[10],
"new_col": fields[11]
}
return json_str
table_schema = 'customer_id:STRING,date:STRING,timestamp:STRING,order_id:STRING,items:STRING,amount:STRING,mode:STRING,restaurant:STRING,status:STRING,ratings:STRING,feedback:STRING,new_col:STRING'
(delivered_orders
| 'delivered to json' >> beam.Map(to_json)
| 'write delivered' >> beam.io.WriteToBigQuery(
delivered_table_spec,
schema=table_schema,
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND,
additional_bq_parameters={'timePartitioning': {'type': 'DAY'}}
)
)
(other_orders
| 'others to json' >> beam.Map(to_json)
| 'write other_orders' >> beam.io.WriteToBigQuery(
other_table_spec,
schema=table_schema,
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND,
additional_bq_parameters={'timePartitioning': {'type': 'DAY'}}
)
)
from apache_beam.runners.runner import PipelineState
ret = p.run()
if ret.state == PipelineState.DONE:
print('Success!!!')
else:
print('Error Running beam pipeline')
Creating a view
view_name = "daily_food_orders"
dataset_ref = client.dataset('dataset_food_orders_latest')
view_ref = dataset_ref.table(view_name)
view_to_create = bigquery.Table(view_ref)
view_to_create.view_query = 'select * from `bigquery-demo-285417.dataset_food_orders_latest.delivered_orders` where _PARTITIONDATE = DATE(current_date())'
view_to_create.view_use_legacy_sql = False
try:
client.create_table(view_to_create)
except:
print ('View already exists')
Run
python code.py -- input file-path
Airflow
pip3 install apache-airflow[gcp]
from airflow import models
from datetime import datetime, timedelta
from airflow.contrib.operators.dataflow_operator import DataFlowPythonOperator
default_args = {
'owner': 'Airflow',
'start_date': datetime(2020, 12, 24),
'retries': 0,
'retry_delay': timedelta(seconds=50),
'dataflow_default_options': {
'project': 'bigquery-demo-285417',
'region': 'us-central1',
'runner': 'DataflowRunner'
}
}
with models.DAG('food_orders_dag',
default_args=default_args,
schedule_interval='@daily',
catchup=False) as dag:
t1 = DataFlowPythonOperator(
task_id='beamtask',
py_file='gs://us-central1-demo-food-order-e90e61dc-bucket/code_written_python_3.py',
options={'input' : 'gs://daily_food_orders/food_daily.csv'}
)
Cloud composer
On Bq, search "Cloud composer" > create envirnoment
